
소소한 개발 공부
논문 리뷰: Attention Is All You Need (NIPS2017) 본문
아래 영상을 보면서 리뷰를 진행했습니다.
동빈나, https://www.youtube.com/watch?v=AA621UofTUA
논문 리뷰: Attention Is All You Need (NIPS2017)
Attention Is All You Need, Ashish Vaswani et al, NIPS 2017. paper link
분석한 내용에 대해 발표한 자료입니다.
0. Abstract
시퀀스 변환 모델은 인코더, 디코더를 포함한 Convolution 네트워크가 많음
가장 좋은 성능의 모델이 attention 메커니즘으로 인코더, 디코더 연결
이 논문은 RNN과 CNN을 뺀 attention 메커니즘 기반 구조, Transformer 제시
Transformer는 병렬성 정도가 높고 학습 시간이 짧음 -> 품질 우수
Attention 기법만 잘 활용해도 좋은 성능을 얻을 수 있다는 것을 제시
WMT 2014 English-to-German translation task에서 28.4 BLEU 달성, 당시 최고 기록 갱신
WMT 2014 English-to-French translation task에서 41.0 BLEU 달성, 8개의 GPU에서 3.5일 동안 훈련한 결과,
당시 최고 모델의 훈련에 비해 적은 시간 동안 훈련
1. 소개
* 목적
Sequence to sequence 문제에서 RNN, CNN 구조를 배제한 Sequence transduction 모델을 만드는 것 (번역 모델)
* Sequence : 단어 같은 무언가의 나열
Ex) 학교, 갔어 > I, went, to, school
Attention 만을 이용한 번역 모델을 만드는 것
* Background
기존 Sequence to sequence 문제에서 RNN, CNN 모델이 우세했는데 아래의 문제가 있음
1. RNN → Long term dependency(장기 의존성) 문제
시퀀스를 정렬하고 입력을 반복적으로 넣어 은닉층 값을 갱신
→ 모든 입력의 영향을 받는데 초기 입력일수록 영향력이 떨어짐
→ 입력 길이에 제한이 생김
2. 시퀀스의 길이 만큼 순서대로 입력을 넣어야 함
→ 병렬 처리가 어려움 → 메모리 및 속도 측면에서 비효율적

* Attention
이전에 Attention이 제안되었으나 RNN과 함께 사용되었음
( 초기 입력의 영향력이 떨어지는 것 방지
그러나 여전히 순서대로 처리되어야 하므로 병렬성 X )
소스 문장의 전체에서 특정 단어에 대해 어떤 정보가 가장 중요한지
가중치를 부여하도록 해 출력 단어를 효과적으로 생성할 수 있음 → 전반적인 문맥 정보를 학습
디코더에서 출력 단어를 만들 때마다 인코더의 모든 출력을 고려 → 소스 문장 내 모든 단어 고려
가장 연관성 있는 단어를 디코더 단어 출력에 활용

본 논문에서는 Attention 만을 활용한 Transformer 를 제안
한 번의 행렬 곱으로 위치 정보가 포함된 전체 시퀀스를 한번에 처리할 수 있음
순차적 입력 x → 병렬 처리 가능 → 메모리 및 속도 효율 향상
2. Transformer 구조
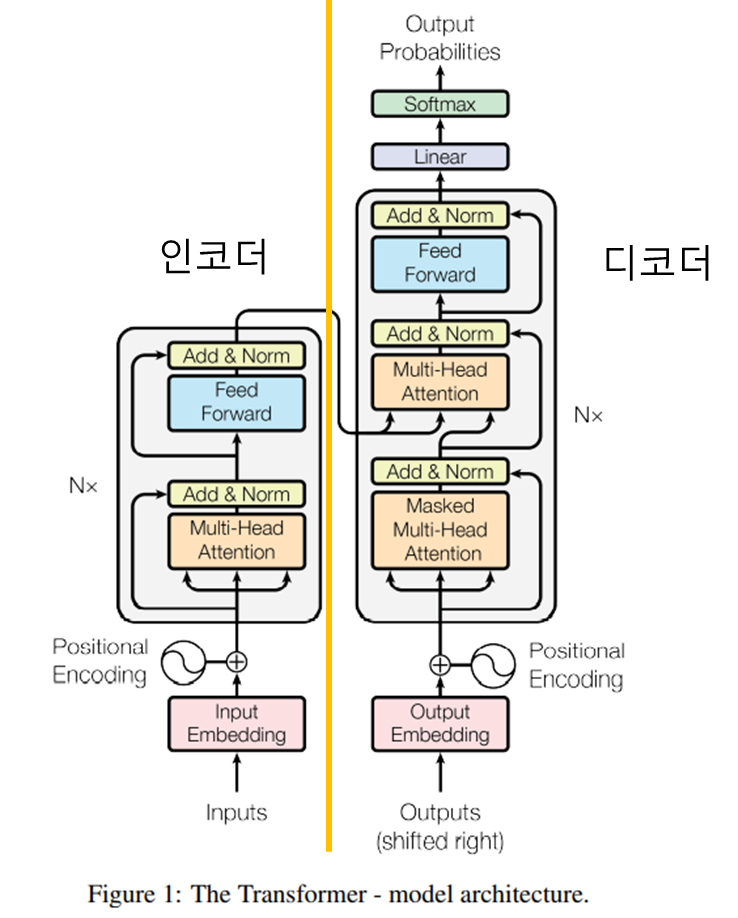
* RNN, CNN을 전혀 사용하지 않음
* 인코더-디코더로 구성
* Attention 과정을 여러 레이어에서 반복
feature 학습 성능을 올리기 위해서
논문에서는 임베딩 차원을 512로 지정
* Embedding

언어에 대한 입력 차원이 많기 때문에 (특정 언어의 단어 개수) 입력 차원을 더 적은 차원으로 축소 시키는 과정
Input Embedding : 소스 언어에 대한 차원 축소
Output Embedding : 타겟 언어에 대한 차원 축소
* Positional Encoding
각각 단어의 순서를 알 수 있도록 하는 인코딩 정보 행렬
RNN을 사용하지 않아 단어 순서를 알지 못하므로 사용
공식을 이용해 각 단어의 상대적 위치 정보를 네트워크에 입력

PE :Positional Encoding
pos :각 단어 번호
i :단어의 임베딩 값 위치
d_model: 임베딩 차원
각각의 입력 문장에 포함된 각 단어의 상대적 위치를 알 수 있도록 주기성을 학습할 수 있도록 만들면 어떤 함수가 들어와도 사용할 수 있음
-임베딩 값을 따로 학습해서 네트워크에 넣을 수도 있다고 하며, 이는 주기함수의 성능과 크게 차이 나지 않는다고 함
* Encoder
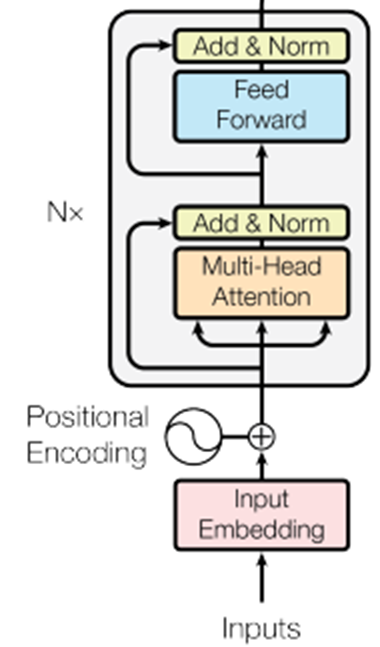
1. Multi-Head Attention
Self-Attention, 소스 문장 내 단어 각각의 연관성(가중치) 계산
2. Add & Norm
성능 향상을 위해 Residual Learning 사용
Normalization
3. FeedForward
순방향 신경망, Relu 함수 사용
FFN(x)=max(0, xW_1+b_1 ) W_2+b_2
Attention과 정규화(Normalization) 과정 N번 반복
각 i번째 레이어는 서로 다른 파라미터를 가짐
인코더의 입력-출력 차원은 동일
가장 마지막 레이어의 출력 값이 Decoder에 들어 감
Residual learning으로 기존 정보를 입력 받으면서 잔여된 부분만 학습하도록 함
-> 초기 모델 수렴 속도가 높고 global optima를 찾을 가능성이 높아짐 -> 성능이 좋아짐
* Decoder

1. Masked Multi-Head Attention
Self-Attention, 타겟 문장 내 단어 각각의 연관성 계산
2. Multi-Head Attention
Encoder-decoder attention, 출력 단어가 소스 문장에서 어떤 단어와 연관성이 있는지 계산
→ 마지막 인코더 레이어 출력이 모든 디코더 레이어(총 N개)에 입력
3. Softmax
Output Probabilities 출력
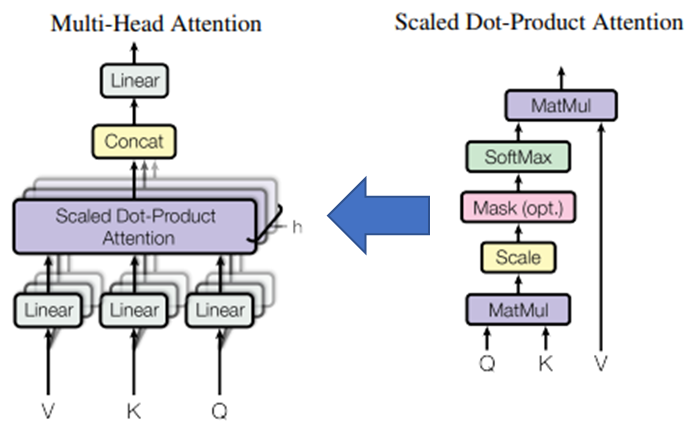
* Multi-Head Attention : Q, K 간 연관성 계산
- 여러 개의 head를 가진다고 해서 Multi-head attention 이라 부름
- 입력으로 들어온 h개 값이 각각 3개로 복제되어 V, K, Q로 쓰임
V: Value(값)
K: Key(키) : 쿼리에 대해 연관성을 물어보는 대상
Q: Query(쿼리) : 다른 단어와의 연관성(가중치)을 찾는 주체
Ex) I, went, to, school 에서 (K/Q) = (I, went, to, school / I)
Encoder-decoder attention은 디코더의 출력 단어가 Q가 되고 인코더의 출력이 K, V가 됨
Linear layer에서 V, K, Q 쌍을 h개 만들어서 Scaled Dot-Product Attention에 각각 넣는 것 -> h개가 된다
마스크 행렬에 마스크 값으로 행렬 좌표에 음수 무한의 값을 넣어 softmax함수의 출력이 0에 가까워지도록 한다
* Scaled Dot-Product Attention
Softmax - 쿼리가 어떤 키와 가장 연관성이 높은 지 구함
MatMul - Value를 곱해 Attention Value를 구함
Mask - 선택적으로 특정 단어의 가중치를 무시하기 위함
Attention Value는 총 h개 만들어짐 -> concat으로 1행으로 붙임
→ 다양한 특징을 학습할 수 있게 함
Linear 레이어를 거쳐 출력을 내보냄 / 입력-출력 차원은 동일
왜 head가 여러 개 인가? – 서로 다른 위치에 있는 서로 다른 표현에 대해 잘 학습할 수 있게 하기 위해 ex) it

* Multi-Head Attention 종류

1. Encoder Self-Attention
소스 문장 각각의 단어가 서로 어떤 연관성을 가지는 지 계산
전체 문장에 대한 특징 학습
2. Decoder Self-Attention (mask)
타겟 문장 각각의 단어는 앞 자리의 단어에 대해서만 연관성 계산
타겟 문장의 단어는 뒤 단어를 미리 알 수 없게 학습
Ex) 나는 학교에 (간다/안 간다/왔다/ … 중에 뭐가 쓰일 지 앞단어는 몰라야 함)
3. Encoder-Decoder Attention
Q는 이전의 디코더 레이어, K, V는 마지막 인코더 레이어에서 가져와 소스 단어와 타겟 단어의 연관성 계산
타겟 단어만 소스 단어 전체를 참조하는 방식
Ex) (나는, 학교에, 간다) 와 (school) 의 연관성 계산
* Encoder-decoder attention은 디코더의 출력 단어가 Q가 되고 인코더의 출력이 K, V가 됨
* 왜 Self-Attention을 사용하나?

N(시퀀스 길이, 단어 개수)이 d(표현 차원, 언어 내 존재하는 단어 수) 보다 현저하게 적기 때문에 계산 복잡도가 훨씬 작다.
* Training
450만개 문장 쌍이 있는 WMT 2014 English-German dataset 학습
3600만개 문장 쌍이 있는 WMT 2014 English-French dataset 학습
8 NVIDIA P100 GPU 사용
Base model - 한 step에 0.4초 / 12시간 동안 100,000 steps 학습
Big model – 한 step에 1.0초 / 3.5일 동안 300,000 steps 학습
Adam optimizer 사용
Regularization


